Git 的核心概念¶
分布式版本控制系统¶
说到分布式版本控制系统,就必须要说一下传统的集中式版本控制是怎么做的。
在集中式的版本控制系统中,代码被保存在一个服务器中,客户端通过远程连接服务器来更改代码。
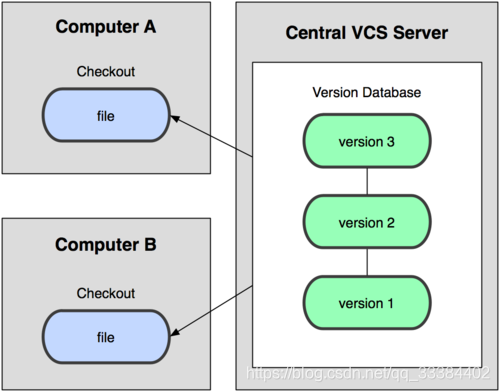
这导致了一旦服务器崩溃,整个项目都面临丢失的风险。
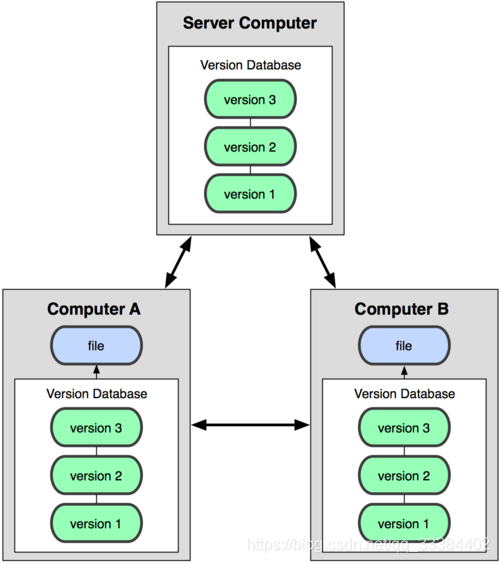
类似 Git 的分布式版本控制的做法稍有不同,客户端每次都要拷贝一遍服务器的代码,然后在本地修改后提交到服务器。
这样,就算服务器的代码丢了,客户端这边有很多备份,就没有关系。
文件监查系统¶
你不可能修改了文件或目录之后,Git 对此却一无所知。
Git 使用 SHA-1 算法计算数据的校验和。通过对比校验和,来判断文件是否改变了。
每过一段时间都要计算一次。所以,如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
记录快照,不比较差异¶
“不比较差异”听起来有点让人困惑,我们来看看传统的做法吧。
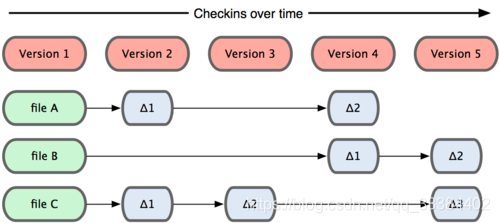
在传统的模式中,每一个文件都维护来一个链表,每次文件更新之后,才会创建一个新的链表项。
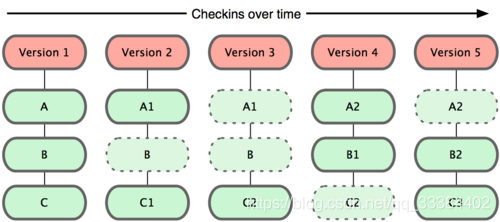
Git 使用的是上图的这种模式,每当文件更新的时候就记录一次快照,如果没有更新,会保存一个快照的指针,指向上一个文件快照。
理由是在回溯的时候指针相比链表可以拥有更好的性能。
文件的三种状态¶
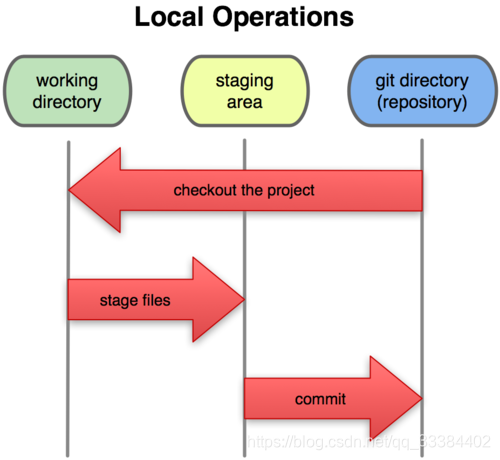
Git 的文件有三种状态,commited、staged、modified。
为什么要设计三种状态?
- 当处于
modified状态的时候,代表文件被修改,但是还没暂存记录,这个时候你可以随意更改文件。 - 当你工作了一半,为了防止数据丢失,可以把
modified状态的文件暂时存储一下,也就是转到了staged状态。如果你反悔了,只要取消暂存,原来的文件又回来了。 - 当一部分工作做完之后,你觉得可以提交到代码仓库里去了,那就把
staged状态的文件转到commited状态,代表了正式提交到代码仓库中。
Info
上面说了,Git 是分布式的,所以第三步只是在本地的代码仓库提交了代码,你还得把本地的代码提交到服务器。
很多大公司有自己的 Git 服务器,更多的个人开发者则喜欢使用类似于 Github、Gitlab、Gitee、Coding 等等的网站来做服务器。
目前 Github 是全球最大的代码托管平台,目前由微软资助。
五对象模型¶
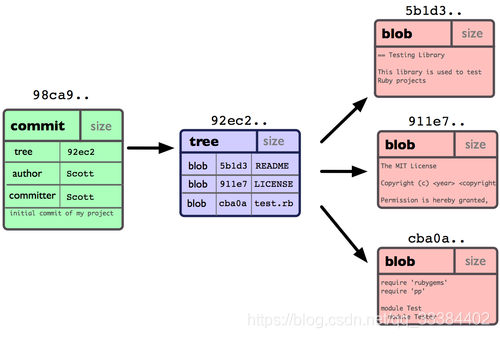
Git 仓库中一次 commit(提交) 被分为 5 个对象,可分为 3 类:
- 3 个 blob 对象 (代表类上面说的3种文件)
- 1 个 tree 对象
- 1 个 commit 对象
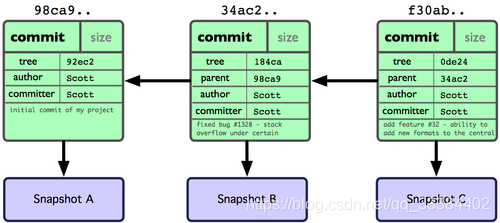
commit之间又是一种链式的关系:
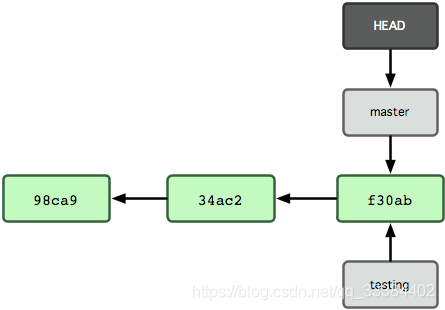
分支的概念¶
分支是平行宇宙。
当他们在一个节点分离之后,就有了自己的发展方向。
其中,有一个 HEAD 指针,是你当前所在的分支,你可以通过改变这一个指针来切换分支。
基于分支的开发模型¶
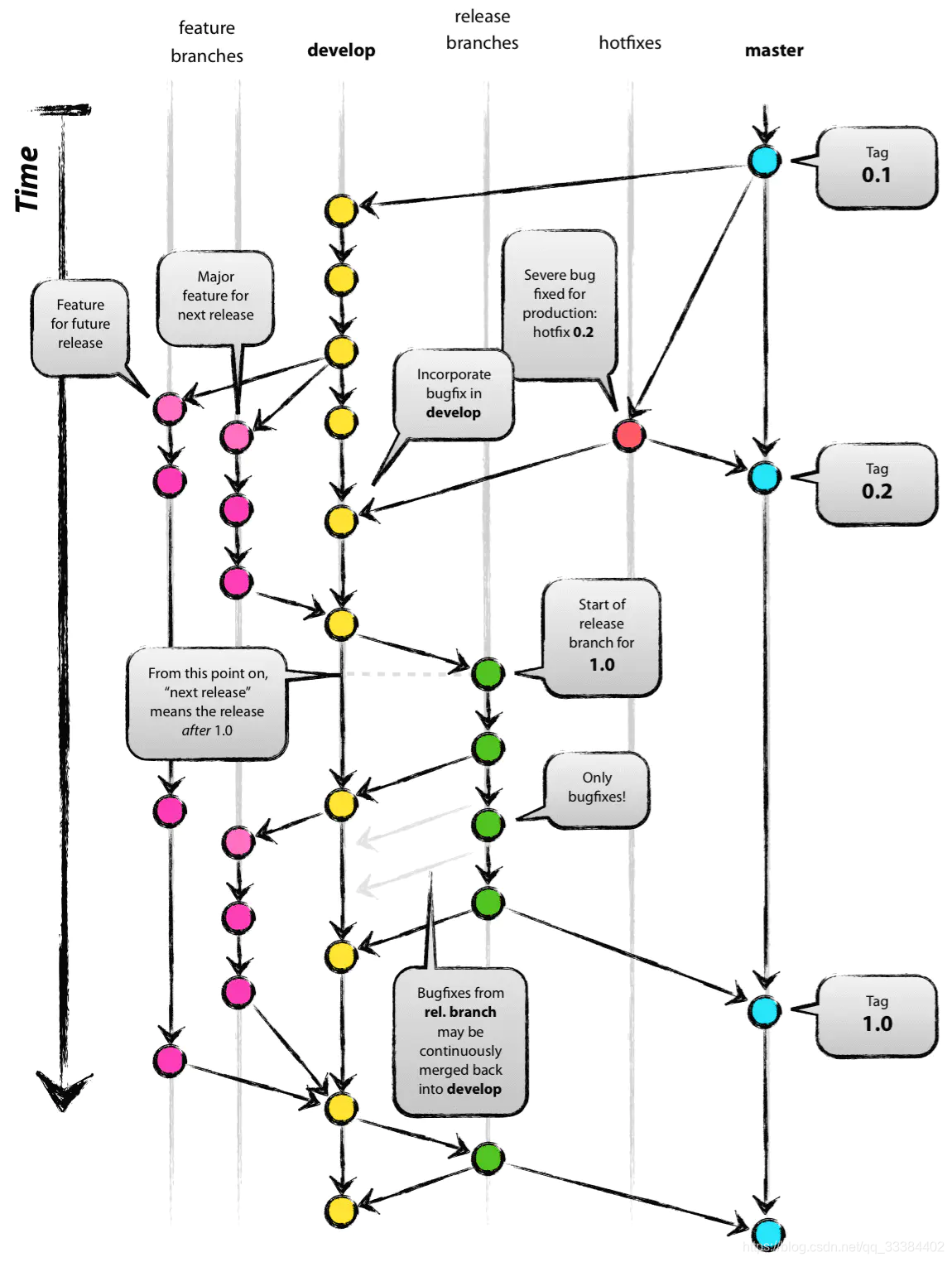
这是一个标准的开发模型,我们不去阐述这么复杂的模型,这里仅仅讨论单分支模型和双分支模型。
看了这张图,你应该知道,所谓的版本管理,就是分支的管理。
单分支模型¶
就是从头到尾都是一个 master 分支。这个没什么好说的。
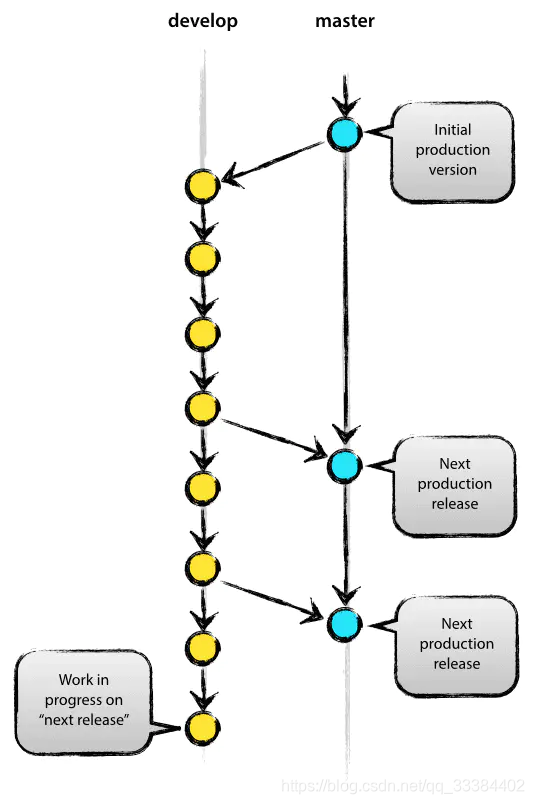
双分支模型¶
或者也可以叫 master/develop 开发模型。
稳定版的代码发布在 master 分支,而一些新功能和特性。还在开发当中,就放到 develop 分支。
冲突¶
一个复杂的 Git 系统中,分支众多,当我们合并分支的时候,很容易遇到冲突。
这个时候就需要手动解决一下冲突,然后再合并。这需要你查看报错的地方,然后去找出来并修改。